Aggregation#
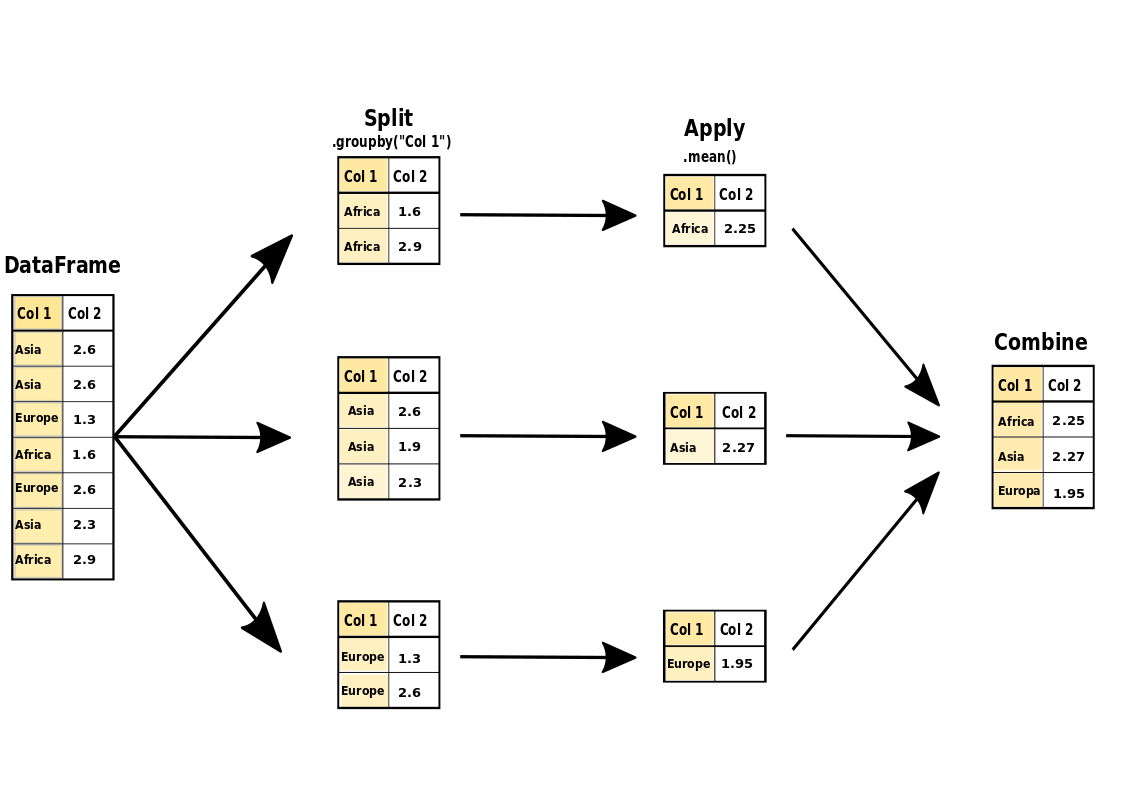
The DataFrame.groupby() statement is very powerful for data wrangling in Python.
The main concept to understand Split-Apply-Combine.
Split the data into groups based on some criterion
Apply an aggregation function to each group
Combine the results to a new DataFrame
Examples#
import seaborn as sns
df = sns.load_dataset("penguins")
# use a predefined aggregation function
df["body_mass_g"].mean()
# calculate the average body mass by species
df.groupby("species")["body_mass_g"].mean()
# calculate the average body mass by two criteria
df.groupby(["species", "sex"])["body_mass_g"].mean()
# save the per-species mean as a new column
df["mean_species_mass"] = df.groupby("species")["body_mass_g"].transform("mean")
# use multiple aggregation functions
df.groupby("species")["body_mass_g"].agg(["mean", "min", "max"])
Split#
How do you want to split your initial DataFrame? There are multiple options:
# 1. by a column
g1 = df.groupby('species')
g1.groups
# 2. by a boolean mask
mask = np.array(([False, True] * 300)[:df.shape[0]])
g2 = df.groupby(mask)
g2.groups
# 3. by a Dictionary with keys on the Index
groups = {1: "group A", 2: "group B",
3: "group C", 4: "group A",
...}
g3 = df.groupby(groups)
g3.groups
# 4. by a function
g4 = df.groupby(len)
g4.groups
# 5. a list of the above
g5 = df.groupby(['species', mask, len])
g5.groups
You can iterate over the groups and inspect each of them separately:
for i, df_group in df.groupby('species'):
print(i, df_group, '\n')
Apply#
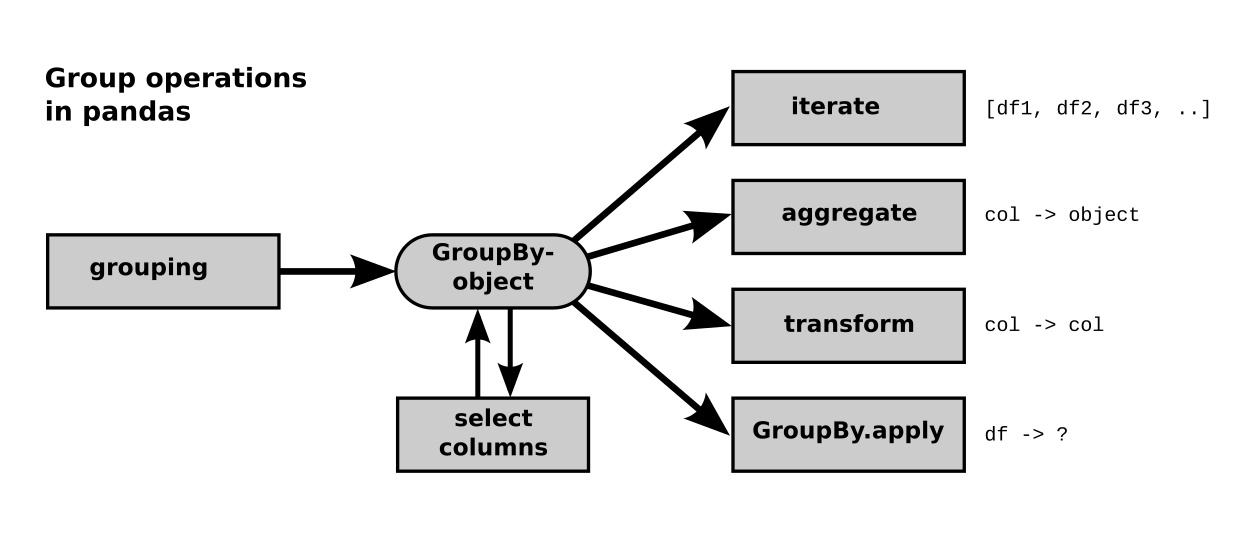
There are three types of functions that you can apply to your groups:
1. Simple Aggregations#
In a simple aggregation, the size of the result is the number of your groups. What aggregation functions can you use?
g = df.groupby('species')
# standard aggregation functions
g.mean()
g.max()
g.min()
g.sum()
g.count()
g.std()
g.median()
g.quantile(0.9)
g.describe()
# Aggregation with selecting columns
g['body_mass_g'].describe()
# Aggregation with a list of function names
g.agg(['count', 'mean', 'std'])
# function name with a label
g.agg([('Total', 'sum')])
# custom aggregation function with parameter
def sum_greater(dataframe, threshold):
for column in dataframe.columns:
return dataframe[dataframe[column] > threshold].sum()
g.agg(sum_greater, threshold=200)
2. Transform#
When using .transform(), the size of the result stays the same.
The result of your aggregation functions is projected to all elements it was calculated from.
# Transform by function name
g.transform('mean')
# Transformation by function reference
g.transform(len)
# Transformation with your own function
def normalize(array):
return array - array.mean()
g.transform(normalize)
3. Apply#
The generic .apply() takes each pd.Series of a pd.DataFrame as input,
applies a specified function to all of them and returns,
depending on the specified function, either a pd.Series or a pd.DataFrame
of flexible size. It aggregates over the pd.Series or not at all.
def first_two(df):
return df.head(2)
g.apply(first_two)
Combine#
In the last step, the results from each group are combined into a new DataFrame. Pandas takes care of this step for you automatically.
Recap#
See also
Recap Exercise: Aggregation#
First, load the penguin data:
import seaborn as sns
df = sns.load_dataset('penguins')
Answer the following questions:
# 1. what is the total mass of all penguins?
...
# 2. how many penguins are from which island?
...
# 3. what is the average body mass of each species?
...
# 4. how long is the longest beak of each species?
...
# 5. what is the mean of each numerical column, per species?
...
# 6. how many female penguins are there for each species?
...
# 7. what is the standard deviation of bill length and depth for each species/sex combination
...